Table of Contents
Are you writing a test specification?
There are various ways to write test specifications, such as making them as test specifications or as test code, depending on the company.
I think it is common for large, historical companies to create test specifications in Excel files.
When editing by multiple people, I think it is also common, at least in Japan, to use suffixes such as _latest, _latest_20230103, _latest_5 to manage versions.
I would like to know the best practices for handling Excel files, but I have no good idea at the moment, so I decided to use a program to make the differences visible in a Git repository and manage them.
However, if you put the Excel file directly into Git, the difference lines are not clearly displayed. TortoiseGit and other tools will also show you the difference, but can you make pull requests and comments there? You usually see the difference on the web page of the repository anyway. And CSV is also a bit unsatisfactory. There are tools that can edit CSV in table format like spreadsheet, but the diff display of the repository should be a simple character-delimited text, which is not easy to read. So, I thought about managing test cases in Markdown. If you can manage it in text, you can also use *nix commands. You can write test cases even if you don’t have Excel, and if you can convert it to Excel, no one will have any trouble. (The tool I used can also convert to CSV, TSV.)
Summary so far
- If you manage it with Git, you won’t have to wonder which version is the latest.
- If you manage it with Markdown, you can see the difference in the pull request. You can also comment there.
- CSV may also break the display
- If you manage it with Markdown, you can use *nix commands.
- If you manage it with Markdown, you can create and edit it even if you don’t have Microsoft Excel.
- If you can convert from Markdown to Excel, you won’t have any trouble when you want to use table format.
Environment tested
- macOS Monterey Version 12.6
- Python 3.10
- meal 0.0.3.32
How to convert Markdown to Excel
Preparation
Install a Python tool called mael.
|
1 |
$ pip install mael |
Create a directory to store the test specifications.
|
1 |
$ mkdir test |
Initialize the folder.
You will be asked which template to use.
For testing, 1: Test case is useful.
|
1 2 3 4 5 6 7 8 |
$ mael init test Initialize /directory/path/test. Which template do you use? 0: Normal 1: Test case Type number: 1[Enter] |
Then, the following files are generated.
|
1 2 3 4 5 6 7 8 |
|--.gitignore |--config | |--columns.yml | |--ignore.txt | `--variables.ini |--README.md |--Scenario 1.md `--Scenario 2.md |
There are various configuration files in config, but you can change them later, so let’s move on to the main test case creation.
Test case description
Scenario 1.md, Scenario 2.md have sample test cases written in them.
Let’s update them.
Edit with vim test/Scenario\ 1.md or something.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
# Scenario 1 ## Summary This is a test. ## List ### Item Login confirmation ### Description Try logging in ### Expected value You can log in --- ### Item Open my page ### Description Click the link "My Page" in the upper right corner ### Expected value My page is displayed. The following four menus are displayed. * Change email address * Change password * Change address * Withdrawal |
Generate Excel file
Run the following command.
|
1 |
$ mael build test |
test/output/test.xlsx is generated.
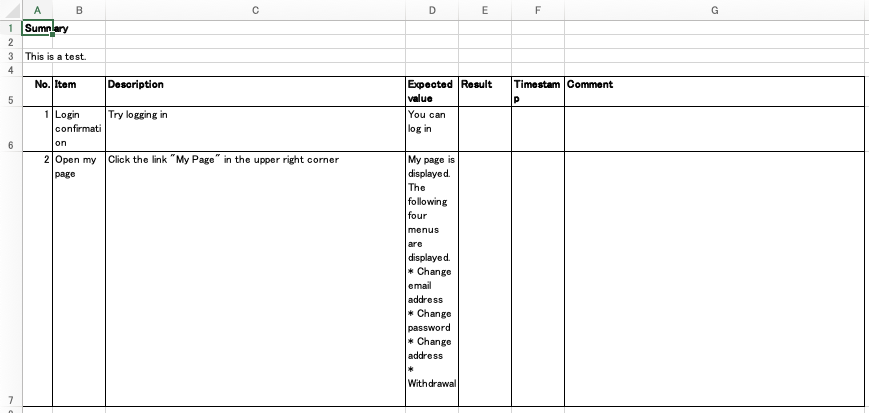
The settings in the config directory add the Result, Timestamp, Comment columns.
You can use them as fields to enter the execution time and comments when performing the test.
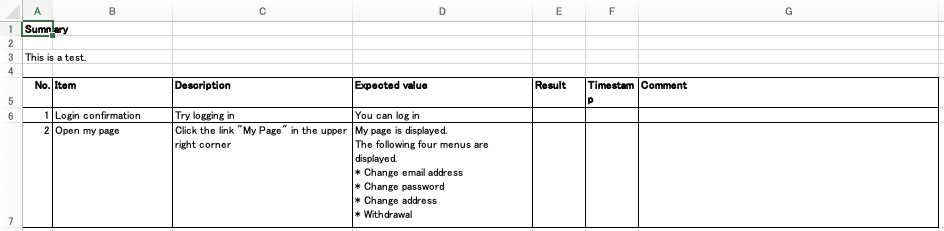
To adjust the column width of “Item”, “Description”, and “Expected Value”, change columns.yml.
|
1 2 3 4 5 6 7 |
column_conditions: Item: width: 20 Description: width: 30 Expected value: width: 30 |
(There are already column settings for Categories, Description, Expected in column_conditions, but you can delete them if you don’t use them.)
And run the command again. Then the column width is changed and output as follows.
Final step
Let’s store the Markdown files in Git. Since we haven’t initialized it yet, we’ll start with git init.
|
1 2 3 4 5 |
$ git init $ git add . $ git commit -m initial $ git remote add origin https://... $ git push -u origin |
Now, you can manage test cases in Markdown files.
mael can output Excel tables if you match the Markdown format, so it is useful for managing various data in Markdown, not just test specifications.
Tips
Use variables
Let’s make variables that can be used repeatedly, such as user names and URLs that appear many times. If it was Excel, you would use cell references or define names.
With mael, you can define variables in config/variables.ini. Well, they are constants.
|
1 2 3 |
URL=https://sample.com USERNAME=admin PASSWORD=abcdefg |
To use the defined variables, enclose the variable name with {{ }}.
|
1 2 3 4 5 6 7 |
# Scenario 2 ## Summary Log in with {{ USERNAME }} / {{ PASSWORD }} at {{ URL }}. ## List ### Test Log in with {{ USERNAME }} / {{ PASSWORD }} at {{ URL }}. |

Change the value of the variable for each environment
Sometimes you want to change the value of the variable for each environment, such as when the website URL or the user name to use is different between the production environment and the development environment.
In that case, you create a variable definition in the form of variables.{environment name}.ini.
For example, create variables.dev.ini as follows.
|
1 |
URL=https://dev.sample.com |
And use the option parameter -e to run the command.
|
1 |
$ mael build test -e dev |
This will create test/output/test_dev.xlsx.
variables.ini is used, but if there is the same variable definition in variables.dev.ini, the definition in variables.dev.ini takes precedence.

Reduce the number of lines in Markdown
Since all the items in the table are arranged vertically, the number of lines in the Markdown file will be long. There are two ways to reduce the number of lines in Markdown.
Don’t use ---
Above, I explained that --- is used to move to the next line.
This is for the sake of how it looks in Markdown, and it is not necessarily necessary.
If the same column value continues, the second one is treated as a new line value.
|
1 2 3 4 5 |
## List ### Column A ### Column B |
| Column |
|---|
| A |
| B |
It is also possible to set it to overwrite the existing line instead of a new line.
Copy when blank
In Excel tables, including test specifications, there are cases where the first and second rows are the same for a specific column. In the following table, the large and medium categories are repeated.
| Large category | Medium category | Small category | Remarks |
|---|---|---|---|
| Tokyo | Chuo-ku | Ginza | TEXT1 |
| Tokyo | Chuo-ku | Tsukiji | |
| Osaka | Kita-ku | Umeda | TEXT2 |
In this case, you can write the repeated part once by setting config/columns.yml.
In the following example, I only wrote the large category “Tokyo” and the medium category “Chuo-ku” once.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
## List ### Large category Tokyo ### Medium category Chuo-ku ### Small category Ginza ### Remarks TEXT1 ### Small category Tsukiji ### Large category Osaka ### Medium category Kita-ku ### Small category Umeda ### Remarks TEXT2 |
There are multiple ways to set config/columns.yml.
A method to set the whole to copy the previous line when blank, and not to copy the remarks,
|
1 2 3 4 5 6 |
global: duplicate_previous_for_blank: true column_conditions: Remarks: duplicate_previous_for_blank: false |
A method to set only the large and medium categories to copy the previous line when blank,
|
1 2 3 4 5 |
column_conditions: Large category: duplicate_previous_for_blank: true Medium category: duplicate_previous_for_blank: true |
The last setting is to set only the whole, and write only the title of “Remarks” for “Tokyo”, “Chuo-ku”, and “Tsukiji”. The last setting requires a little change in the Markdown file.
|
1 2 |
global: duplicate_previous_for_blank: true |
|
1 2 3 4 5 6 7 |
... ### Small category Tsukiji ### Remarks ... |
Output in CSV/TSV
You might end up thinking CSV anyway, but CSV is a hard-to-discard format for checking in the CLI.
You can output in CSV/TSV by using the -f option when running mael build. The default is -f excel.
|
1 2 |
$ mael build test -f csv $ mael build test -f tsv |
Convert existing Excel procedure to Markdown
To use mael, you need to have the specification in Markdown. However, it is quite difficult to write down the existing specifications in Markdown by hand. So, I use pandas to convert it to Markdown.
You can read Excel with read_excel, and output it as Markdown.
Sample code
I used jupyter notebook and pandas to process it.
First, read the data.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
import pandas as pd sheet_name = "test_steps" df = pd.read_excel( 'test.xlsx', sheet_name=sheet_name, # if there is a sheet specification header=5, # header row # specify the columns to use here if any usecols=[ 'ID', 'Large category', 'Medium category', 'Small category', 'Description', 'URL', 'Normal/Abnormal', 'Expected result', 'Comment' ] ) |
Output the data to standard output and check it.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
d = df.fillna('').to_dict(orient="record") l = len(d) def write(name, d, f=None): print("#", name, file=f) print("##", "Summary", file=f) print("##", "List", file=f) for i in range(len(d)): h = d[i] for k, v in h.items(): print("###", k, file=f) if len(str(v)) > 0: print(v, "\n", file=f) print("\n", file=f) print("---", "\n", file=f) write(sheet_name, d) |
Finally, output to a file.
|
1 2 |
with open('exported.md', "w") as f: write(sheet_name, d, f=f) |
I want to put a README.md file that can’t be put in Excel.
Create config/ignore.txt and write README.md in it.
|
1 |
README.md |
All Markdown files are read as test scenarios, so if you have something you want to keep separate, put it in ignore.txt.
Summary: How to create Excel test specifications with Markdown
- Initialize with
mael init test_dir. -
Edit the Markdown file and create test cases
- Write Summary and List.
- Lines are easy to read as Markdown when separated by
---. If you want to reduce the number of lines, you can omit them. - If you use variables, use
test_dir/config/variables.iniandtest_dir/config/variables.{environment name}.ini. - If you want to adjust the column width, use
config/columns.yml.
-
Create Excel with
mael build test_dirandmael build test_dir -e {environment name}.- You can also convert to CSV/TSV with
-f csvand-f tsv.
- You can also convert to CSV/TSV with
Postscript
I thought Gauge might be good, but I wondered if it would be hard for non-engineers to see. I also thought Pandoc might be one, but I’m not sure if Pandoc is suitable for test specifications. mael does not have the function to insert figures, so I think Pandoc is also good, but I think it is not a problem because you should write it in words anyway. I think mael is better because Pandoc does not have the function to copy the value of the previous line to the blank part.




